Experiment with GIN index of PostgreSQL DB
PostgreSQL provides the index methods B-tree, hash, GiST, SP-GiST, GIN, and BRIN. Users can also define their own index methods, but that is fairly complicated. In this article, I will discuss the GIN index. GIN index is a very useful index method for a query, count, etc.
Use cases GIN index:
- Full-Text search(tsvector)
- Array Data Type
- JSONB
"GIN stands for Generalized Inverted Index. GIN is designed for handling cases where the items to be indexed are composite values, and the queries to be handled by the index need to search for element values that appear within the composite items. For example, the items could be documents, and the queries could be searches for documents containing specific words."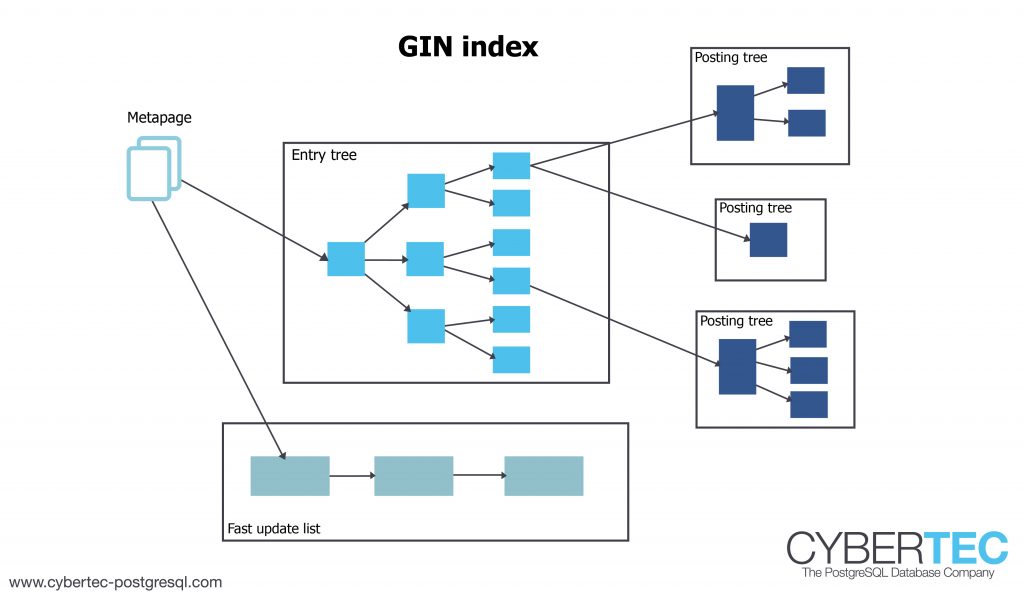
Image credit: Cybertec Postgresql Create test data
The example given is done with PostgreSQL9.6 version (psql client 11.2 ) and Ubuntu 18.04. Machine hardware is RAM 8 GB and Core i5. Create a table with random data by following SQL command over psql client.
CREATE TABLE test_table as select s, md5(random()::text) from generate_series(1, 10000000) s;
By this created two columns. first one is s and another one is md5. Now let’s search a text from our generate data.
select * from new_test where md5 ilike '%b9e2747b6a98a277c2449f2a8969bd1e%';
I searched the last row data from the table. It quite slow brings to our result. The query time is 10132.924 ms or almost 10 seconds without GIN index.
Let’s create GIN an index of the md5 column. By following SQL command.
CREATE EXTENSION IF NOT EXISTS pg_trgm;CREATE INDEX new_table_search_idx ON new_test USING gin(md5 gin_trgm_ops);
It will take time for creating index 10000000 rows. Now recall the query.
select * from new_test where md5 ilike '%b9e2747b6a98a277c2449f2a8969bd1e%';
It will take only a few milliseconds. Second query time is 62.219 ms. Obviously, this is a major improvement in our query.
To be continued …