System Design Interview: Partial Failure & Durability
After talking about idempotency, I thought I’d share another good follow-up question:
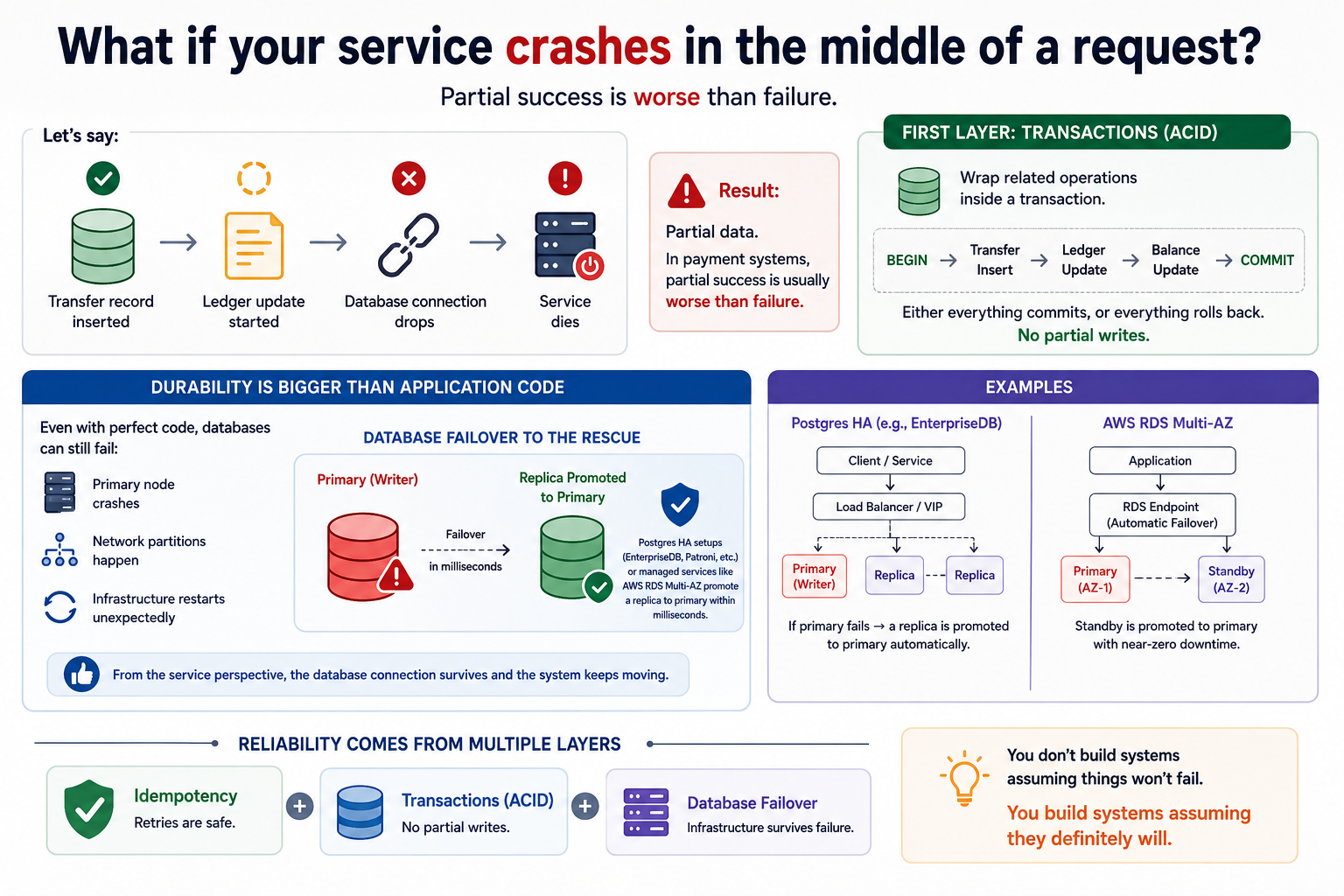
“What happens if your service crashes in the middle of a request?”
Let’s say:
- transfer record inserted ✅
- ledger update started ❌
- database connection drops
- service dies
Now you have partial data.
And in payment systems, partial success is usually worse than failure.
The first answer most people give #
👉 Use database transactions (ACID).
Yes — that’s correct. And it’s the first layer.
Wrap related operations inside a transaction so either everything commits or everything rolls back. No partial writes, no inconsistent state.
But real systems taught me something important:
Durability isn’t only an application problem.
The layer most people miss #
Even if your code is perfect, databases can still fail:
- primary node crashes
- network partitions happen
- infrastructure restarts unexpectedly
That’s why production systems rely heavily on database failover.
Postgres High Availability setups — EnterpriseDB (which I’ve personally used to build a local cloud database environment), Patroni, and others — or managed services like AWS RDS Multi-AZ can promote a replica to primary within milliseconds.
From the service perspective, the database almost never truly “goes down”.
Reliable systems are layered #
Reliable systems usually come from multiple layers working together:
- Idempotency → retries are safe
- Transactions → no partial writes
- Database failover → infrastructure survives failure
You don’t build systems assuming things won’t fail. You build systems assuming they definitely will.